


")

We are selling CRAFT-IT, a new advanced image processing software that enables overwhelming labor-saving and automation of image processing construction.
In addition, in order to make it easier for you to experience the beauty of this software, we are offering a limited-time license that can be used casually.
We are also commissioned to develop filters using CRAFT-IT.
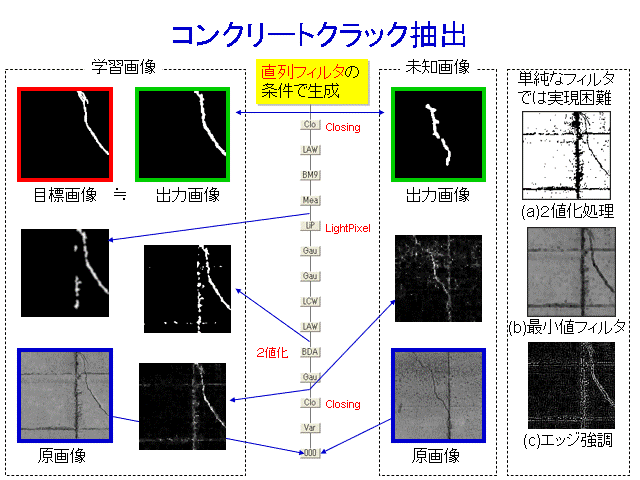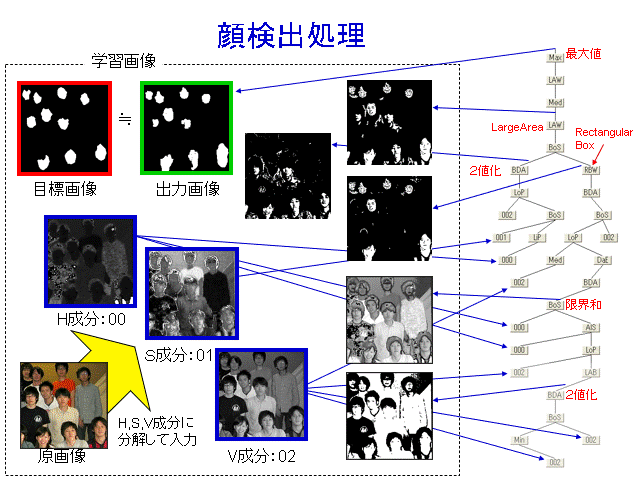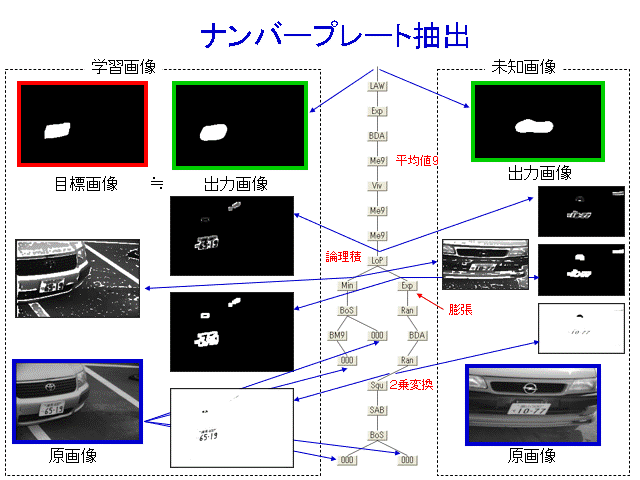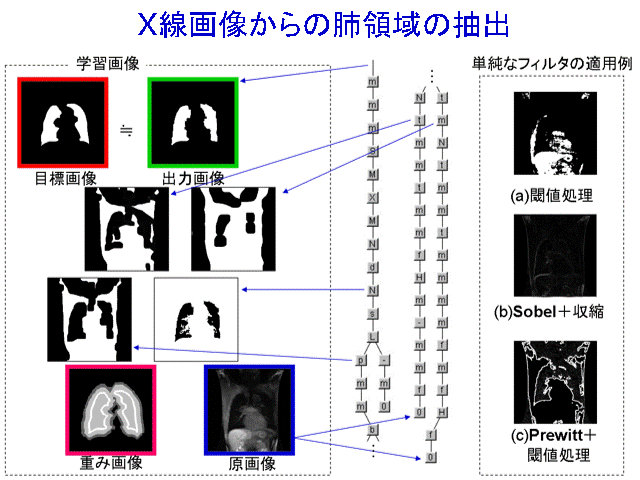
CRAFT-IT can be used for a variety of cases. These filter structures are automatically generated.
AI Technology・Development

Development of a software to control vehicles automatically through a camera
We have developed a software to control vehicles automatically through a camera, just by adding "dots" on its control di・・・・
More details>>
AI Technology・Development
“UbiMouse”, non-contact operation AI software that enables operation without touching the screen
AI software that can be operated without touching a screen and controlling a mouse Smartphone and PC can be op […・・・・
More details>>
Development・Robot Technology

Remote-controlled construction robots for firefighters rescue operation
We have developed an remote-controlled construction robot working with a rescue team, and have delivered nine units to n・・・・
More details>>
Development・Robot Technology

Explosion-proof work robot manufacturing · explosion-proof equipment development consulting
We design and manufacture autonomous mobile robots that can work in flammable gas filled environment that may explode. ・・・・
More details>>
Robot Technology
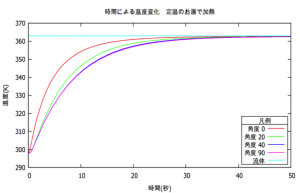
Numerical analysis
Numerical analysis of data measured with various sensors and signal processing. We are developing numerical analysis an・・・・
More details>>
Robot Technology

A.I. & Robot technology
We develop custom-made robots according to your request. For customers who are unable to make specifications and design,・・・・
More details>>